

Stable Diffusion
Stable Diffusion
前言
近年来,AI绘画以颠覆性的创造力席卷艺术与科技领域。从社交媒体的表情包到电影概念设计,从电商产品渲染到独立艺术创作,生成式AI正重新定义“视觉创作”的边界。在众多工具中,Stable Diffusion(SD) 凭借其开源基因与技术自由度,成为开发者、设计师与极客的首选武器。本篇教程我将会从零开始带你入门,AI绘画的神秘面纱
为什么选择Stable Diffusion?
原因很简单免费
目前市面上的AI绘画服务看似很多其实大多数都是订阅付费制,而SD开源免费,但是上手难度和学习成本略大,并且非常吃电脑配置(显卡、内存)但是相信我如果你真的能学会SD,收获会非常大
Stable Diffusion 需要什么配置的电脑
N卡(英伟达Nvida独立显卡)首选,效率远超集显/AMD/Intel显卡和CPU渲染,最低10系起步,体验感佳用40系,显存最低4G,6G及格,上不封顶;内存最低8G,16G及格,上不封顶;硬盘可用空间最好有个200G朝上,固态最佳。
圆规正转 前言部分差不多了,让我们开始第一步安装SD模型
安装
本篇教程中我们将以B站秋葉aaaki大佬所发布的Stable Diffusion WebUI教你如何下载安装
本体的SD其实是运行在命令行终端中的,对非专业人士其实非常不友好,但是因为SD开源后很快就有一位越南的开发者适配了web版的UI界面,让命令行操作变成了可视化操作。而本篇教程中使用的则是秋叶大佬改后的,集模型下载,环境配置,web端生图多功能合一的整合包
首先在bilibili搜索秋葉aaaki大佬关注后点击私信,即可得到最新版的整合包网盘链接
初学者只选择启动依赖和整合包本体的压缩包即可
下载解压放到电脑的空余磁盘的根目录
解压密码关注秋葉aaaki大佬后私信获得
先运行启动器依赖,应该会提示你安装python及其相关组件,这里我们一直点同意和下一步即可。
然后进入SD解压后的的目录
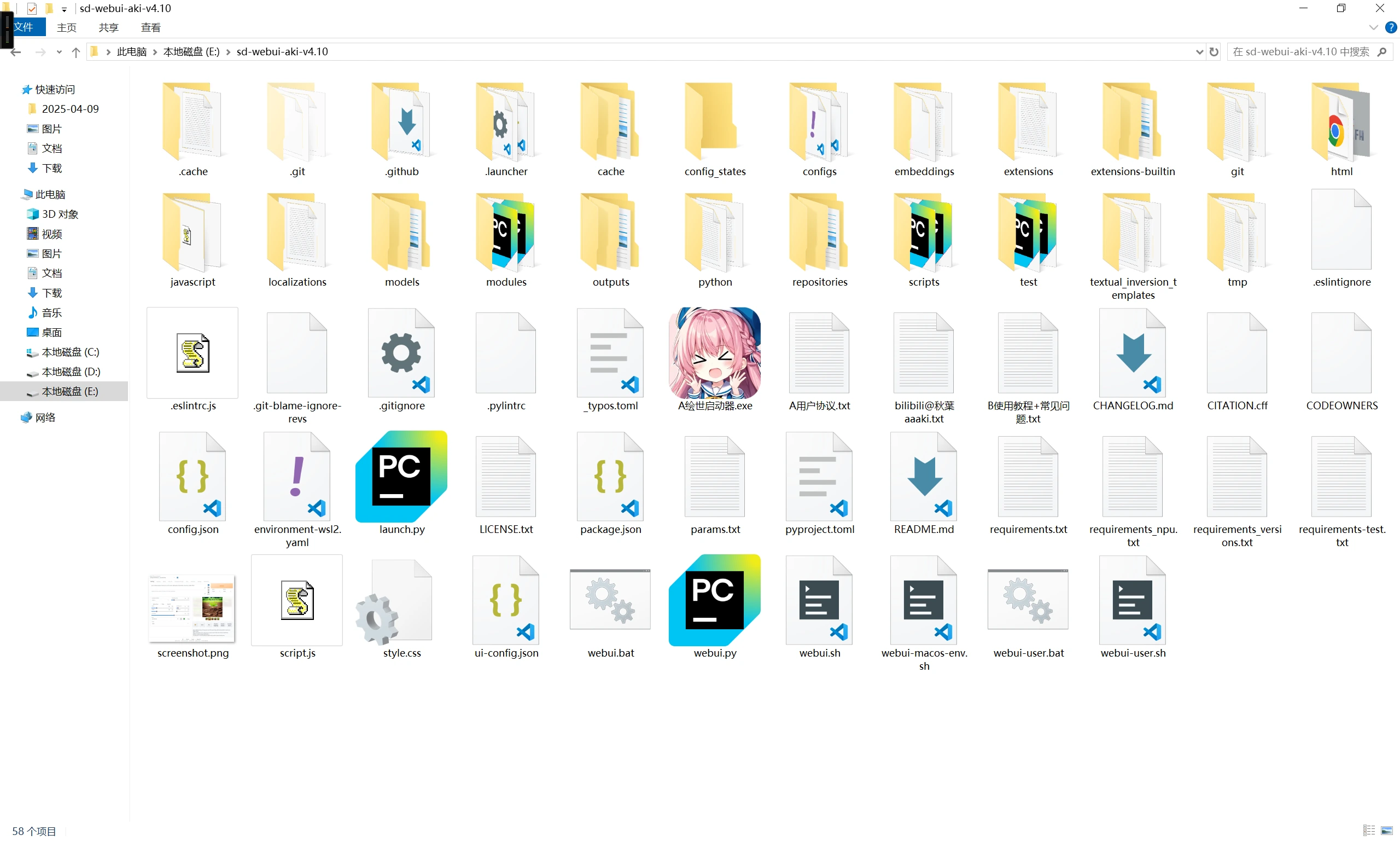
点击的这个叫做AI绘世启动器的粉色小人执行启动器程序,这时你应该听到你的显卡风扇开始狂转了,这是正常现象,不要担心。
然后你会看到,这样一个软件界面
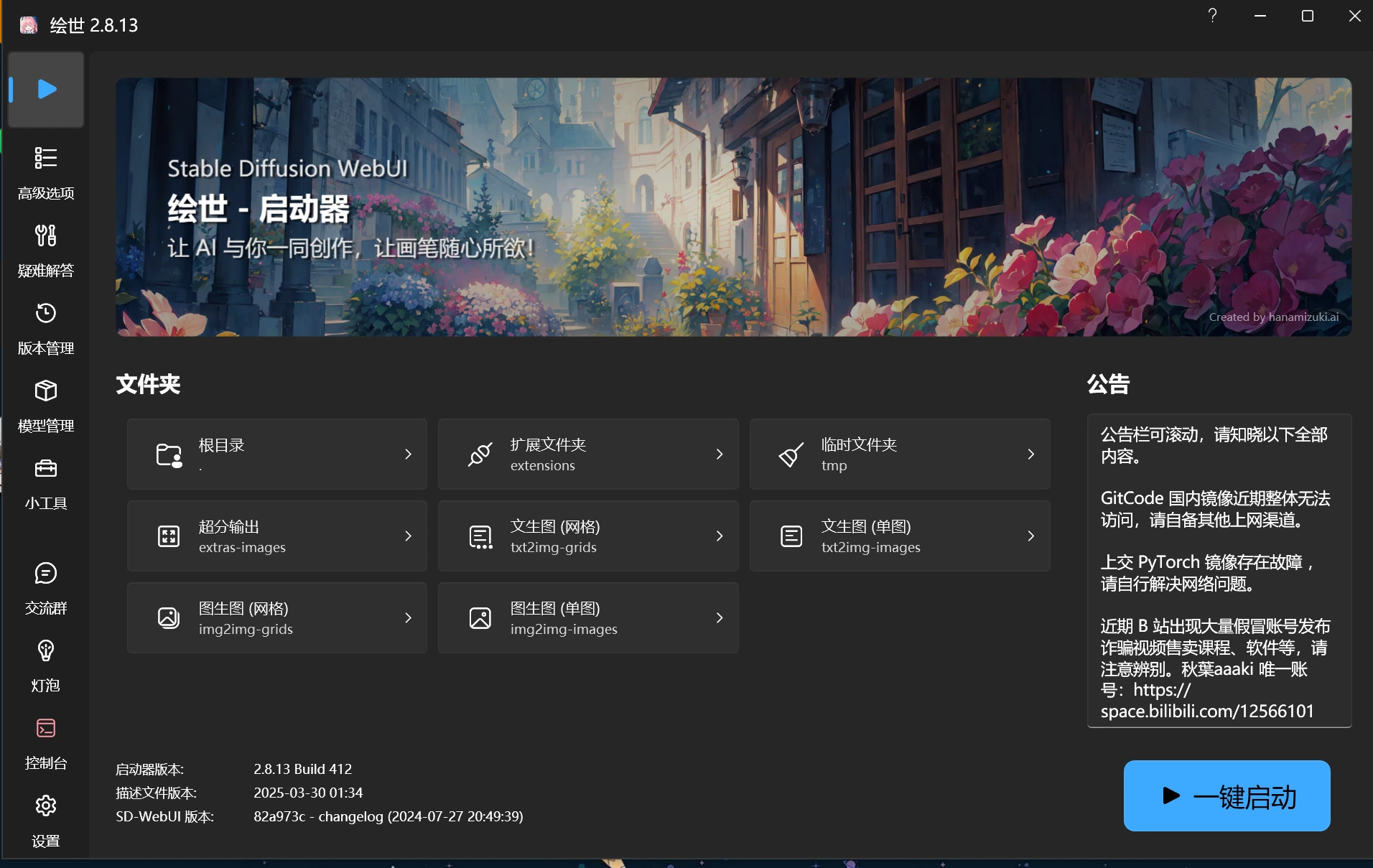
基础配置
完成上述步骤以后我们的SD整合包,其实就已经安装完成了
接下来进行一些简单的参数设置来使,SD运行的的更适合我们的电脑设备
尽可能的减少报错问题
高级选项设置
点击左边侧栏高级选项
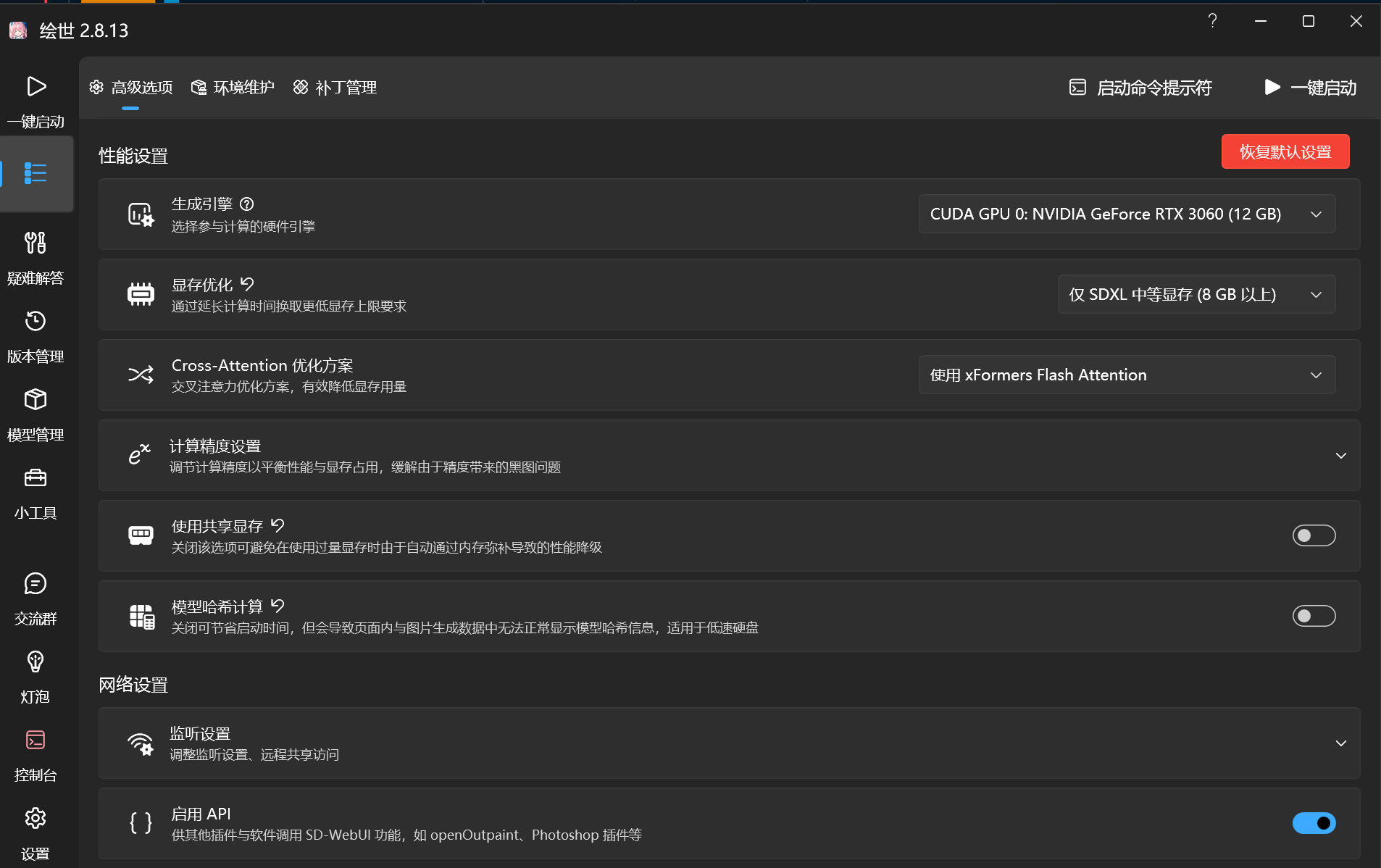
- 生成引擎 选择我们电脑的独立显卡,我的为RTX3060(12G)
- 显存优化 要根据自己显卡的实际显存大小来调整,不要盲目调高,AI绘画对GPU的压力非常大,拉的太高会可能会导致GPU不稳定
如何查看自己的显卡的显存大小
win+shift+esc 快捷键打开任务管理器面板
点击性能选项卡
左侧栏找到你的的显卡型号(一般是最后一个)
此时我们可以看到一个叫做专用GPU内存的参数这就是你的显存大小了
- 共享显存 不是很建议开启,会严重印象你出图的速度.除非在接下来的测试学习中经常会遇到爆显存的问题
共享显存就是在显存不足时,将部分数据从显存交换到内存,需要时再调回显存。但频繁的内存交换会导致CPU变得繁忙.影响出图速度
- 模型哈希计算 推荐开启
- 其他 对于初学者保持默认即可
模型管理
点击左侧 模型管理 选项卡
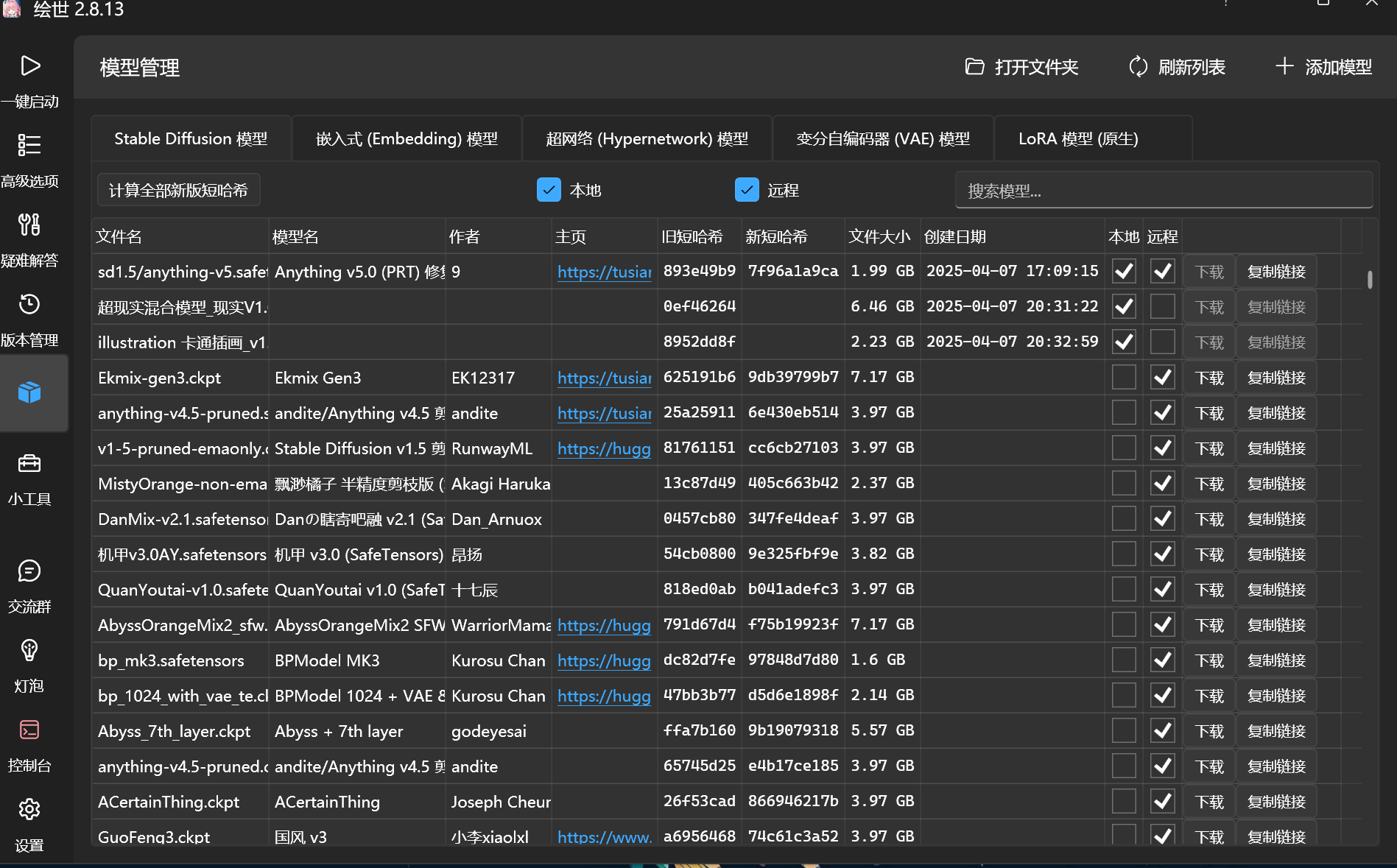
此处我需要先讲解SD的一个核心概念模型
在SD生态中,模型主要分为以下几类,各自承担不同功能:
大模型(Checkpoint/底模)
作用:决定生成图像的主要风格和基础能力,如真人写实、二次元或2.5D风格。
文件格式:.ckpt或.safetensors,体积通常2-7GB。
特点:训练数据量大,需本地部署,可通过微调(如LoRA)扩展功能。
VAE模型(变分自编码器)
作用:负责图像的颜色渲染和细节增强,类似“滤镜”。
常见类型:如vae-ft-mse-840000(写实优化)、kl-f8-anime(二次元优化)。
注意事项:部分大模型已内置VAE,额外加载可能导致冲突。
LoRA模型(低秩自适应模型)
作用:通过轻量化微调(几十MB到几百MB)实现特定风格(如人物、服饰)
使用方式:需配合大模型,提示词语法如lora:模型名:权重。
Embedding模型(文本反转)
Embedding(嵌入模型,又称文本反转模型)是一种通过反向训练将复杂提示词(Prompt)压缩为单一关键词的轻量化工具。其核心功能是:
语义压缩:将冗长的提示词(如负面描述或特定风格指令)编码为一个短关键词。
效率提升:避免重复输入高频提示词,简化工作流。
风格控制:通过关键词快速调用预设的艺术风格或规避特定图像缺陷(如崩坏的手部)
看不懂吧?
看不懂就对了
没关系现在你已经基本掌握了SD的基本概念和基础设置
下一步就是Stable Diffusion 启动!
Stable Diffusion-web-ui
点击软件左侧第一个选项卡
点击右下角一键启动图标
等待片刻,你会看到
终端会有命令行与进度条加载
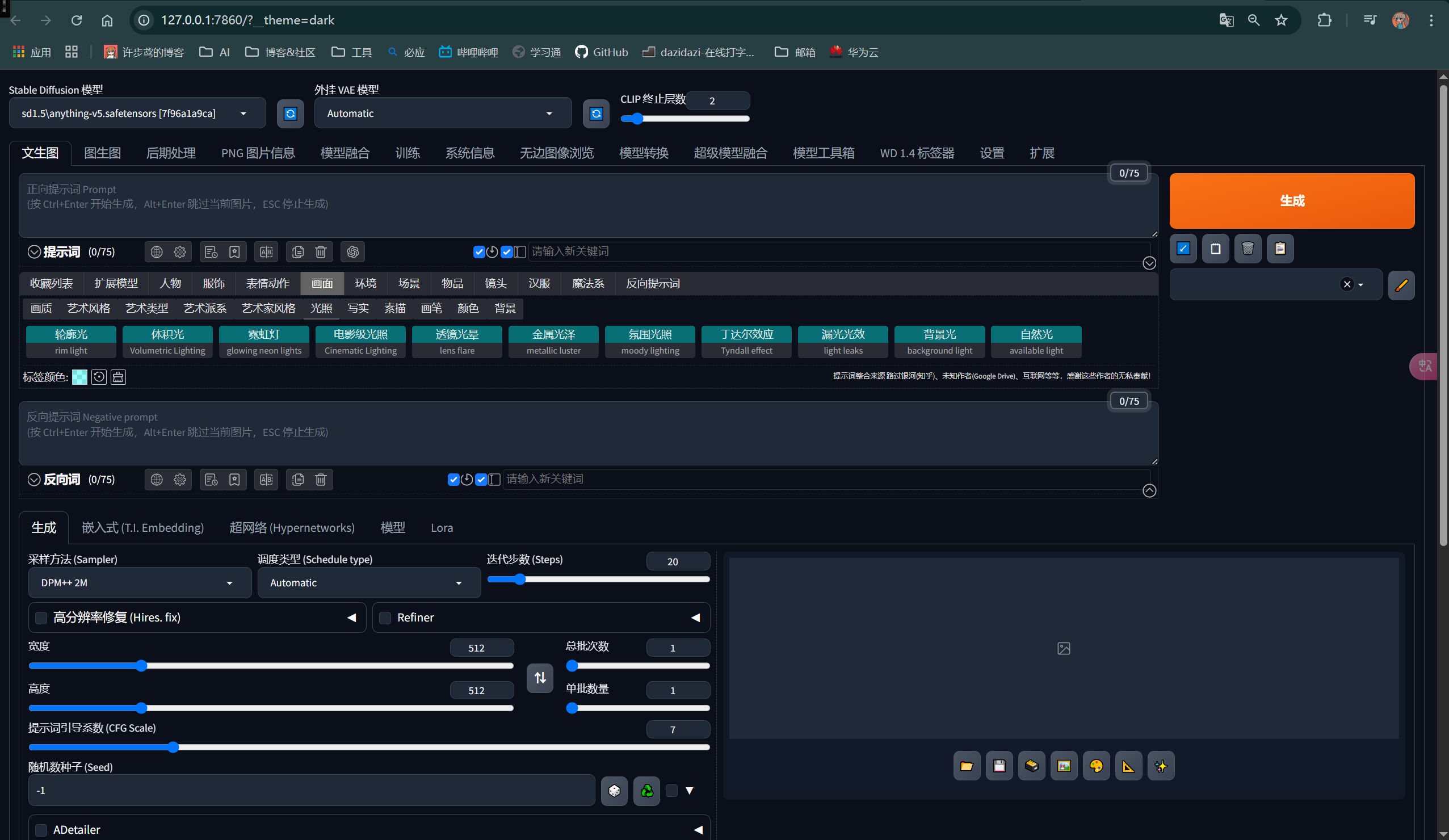
稍后会在本地浏览器看到sd-web-ui了
web-ui 参数详解
- 顶部选项卡
Stable Diffusion 模型:选择当前使用的基础模型。
外挂 VAE 模型:选择外挂的VAE模型,用于图像的编码和解码。
CLIP 终止层数:设置CLIP模型的终止层数,影响生成图像的语义理解。 - 生成按钮
生成:点击此按钮开始生成图像。 - 正向提示词 (Prompt)
输入框:用户可以输入描述生成图像的文本提示。
收藏列表:提供预设的标签和关键词,帮助用户快速构建提示词。
标签词:提供各种标签词,如“轮毂光”、“体积光”等,用于细化图像效果。 - 反向提示词 (Negative prompt)
输入框:用户可以输入不希望出现在生成图像中的内容。
收藏列表:提供预设的反向标签和关键词。 - 参数设置
采样方法 (Sampler):选择采样算法,如DPM++ 2M。
迭代步数 (Steps):设置生成过程中迭代的步数,通常步数越多,生成的图像越精细。
高分辨率修复 (Hires. fix):启用高分辨率修复功能,提升生成图像的分辨率。
Refiner:启用Refiner模型,进一步优化生成的图像。
宽度和高度:设置生成图像的尺寸。
提示词引导系数 (CFG Scale):控制提示词对生成图像的影响程度。
随机数种子 (Seed):设置随机数种子,确保生成结果的可重复性
文生图
先了解一下文生图的基本语法吧!
一、基本语法结构
1. 正向提示词(Prompt)
- 功能:定义生成目标,包括主体、风格、细节等。写你想要的
2. 负向提示词(Negative Prompt)
- 功能:排除不想要的元素(如畸变、低质量)。 写你不想要的
3. 语法规则
- 逗号分隔:用逗号分隔不同关键词,顺序影响权重(靠前权重更高)。
- 括号增强:
(keyword)默认权重1.1,多层括号叠加(如((keyword))权重≈1.21)。 - 数值权重:通过
(keyword:权重值)精确控制,如(glowing eyes:1.5)。
二、参数设置与生成优化
1. 关键参数
- CFG Scale(提示词相关性):
- 推荐范围:7-12(过高易生硬,过低偏离描述)。
- Sampling Steps(采样步数):
- 平衡速度与质量:推荐20-30步。
三、常见错误与解决方案
| 问题 | 原因 | 解法 |
|---|---|---|
| 生成内容偏离描述 | 提示词冲突或权重分配不当 | 使用否定词排除干扰,调整权重平衡 |
| 图像模糊或畸变 | 分辨率不足或模型不匹配 | 切换VAE模型,启用高分辨率修复 |
| LoRA/Embedding未生效 | 文件路径错误或触发词拼写错误 | 检查模型加载路径和关键词一致性 |
四、最佳实践总结
- 分层描述:从主体到背景逐级细化(如“人物→服饰→场景→光影”)。
- 活用模板:
(quality), (style), (subject), (details), (environment) - 迭代优化:通过调整权重和添加否定词逐步逼近目标效果。
ok以上部分就是有关于文生图的基本用法了
接下来将进行第一个小测试,使用基本的文生图功能来生成一张图。来帮助理解各个参数的作用
- 先想提示词
比如我想写一个穿着汉服拿着扇子的古风小姐姐在荷塘边乘风的图片 - 按照上面的的总结应该按照人物→服饰→场景→光影的主次顺序来写这个提示词
人物:年轻女性,手持扇子
服饰:传统汉服,细节丰富的面料纹理
场景:荷花池边,传统建筑与柳树为背景
光影:自然光线,宁静氛围
其他:优雅姿态,飘动的衣袖,精致面部特征,传统发饰,鲜艳的荷花,平和表情,清晰聚焦,自然色彩,传统中国元素
这样应该差不太多了,但要注意SD不能直接使用中文,我们需要把这个翻译成英文。
还有负面提示词需要把我们不想在画面中显示的元素写出来如:错误的人体透视,错误的手指,畸形的比例,低分辨率等
翻译好后的提示词
人物:A young woman holding a round fan
服饰:Traditional Hanfu
场景:By a lotus pond, traditional architecture and willow trees
光影:Soft natural lighting, serene atmosphere
其他:Elegant pose, flowing sleeves, delicate facial features, traditional hair accessories, vibrant lotus flowers, peaceful expression, sharp focus, natural colors
将中文删掉然后复制到提示词里
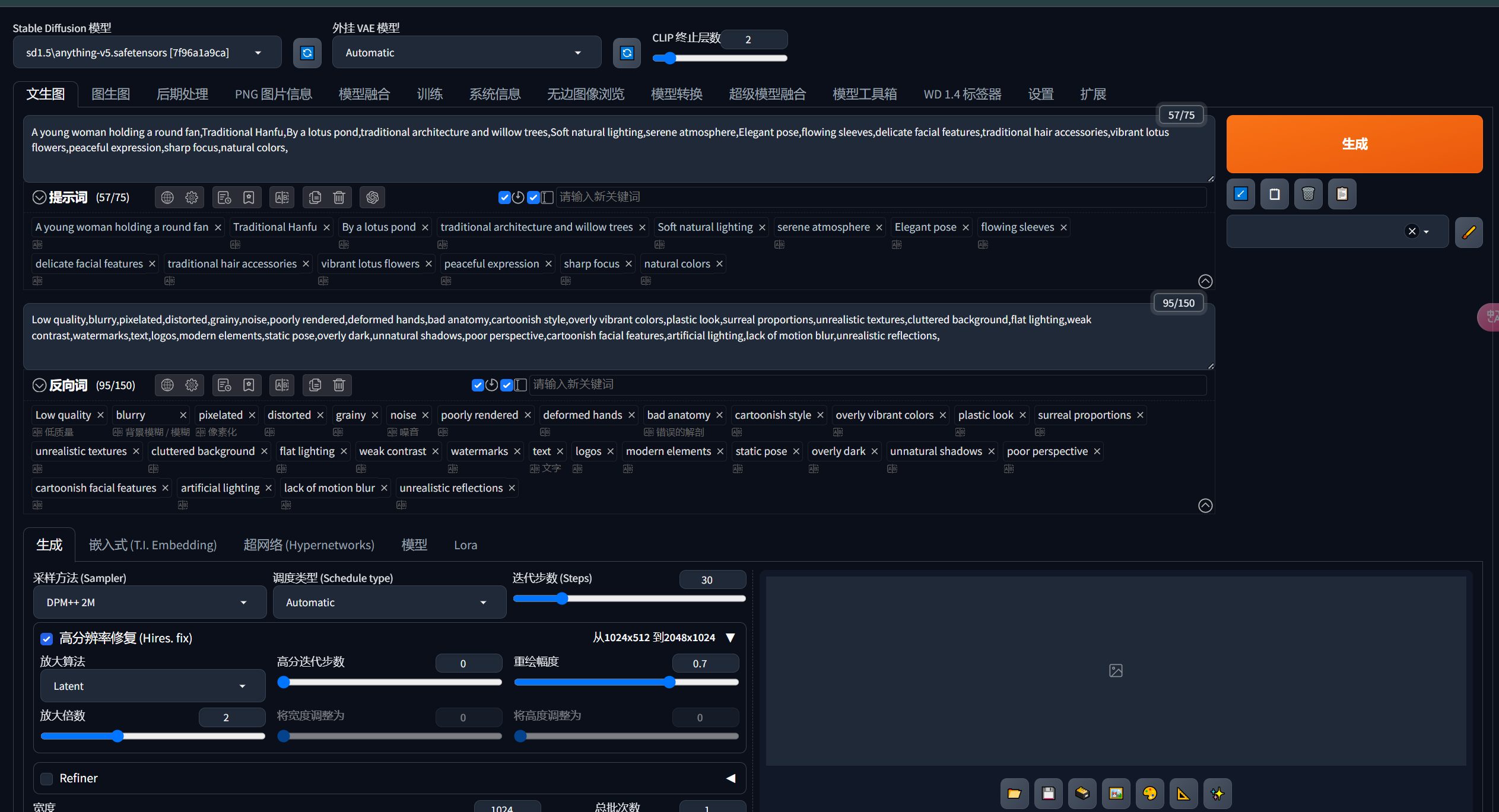
设置图片比例,设置高清修复
然后点击生成

当当!这张图片就生成了
等等? 为啥是二次元风格的
还记得前面的模型的概念吗,秋叶大佬的整合包的基本大模型是一个偏二次元风格的SD模型
如果需要真人画风的,我们可以去各种开源站点下载(这个后面会讲)
我提前准备了一个真人风格的底模
现在生成完之后什么都不要做,点击切换模型
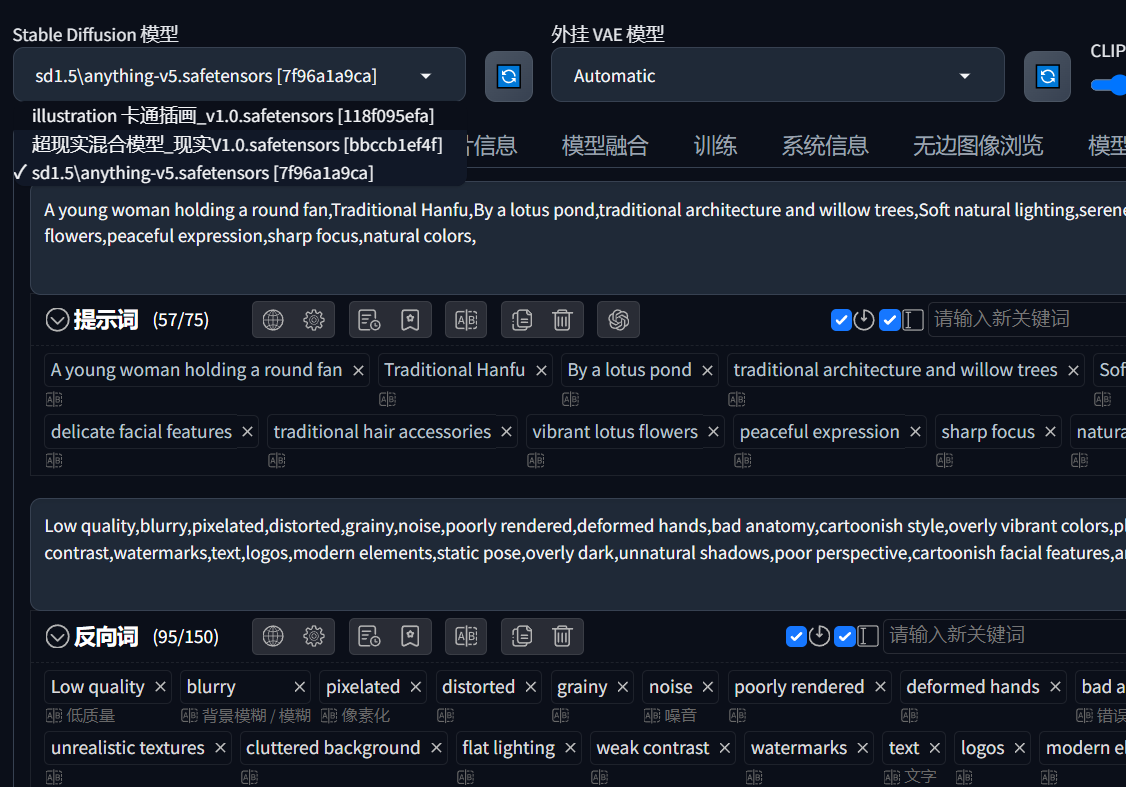
点击现实模型等待加载,然后重新生成一份图片

当当当!大成功!
池塘,垂柳,古风小姐姐,完美表达了所给出的提示词
关于文生图的就先讲到这里吧,接下来我会教大家怎么下载模型
国外的站点大部分都被墙了,我们可以在国内的一些镜像站点找到
- C站,最大的AI绘画交流站
- huggingface(抱脸网国内镜像) 全球最大的AI模型站,不止AI绘画
- 哩布哩布 国内比较火的AI绘画社区,可以在线生成下载模型。
- 土司 AI绘画社区提示词分享社区,也可以在线下载模型
